Pipelines in Microsoft Fabric encapsulate a sequence of activities that perform data movement and processing tasks. You can use a pipeline to define data transfer and transformation activities, and orchestrate these activities through control flow activities that manage branching, looping, and other typical processing logic. The graphical pipeline canvas in the Fabric user interface enables you to build complex pipelines with minimal or no coding required.
Core pipeline concepts
Before building pipelines in Microsoft Fabric, you should understand a few core concepts.
Activities
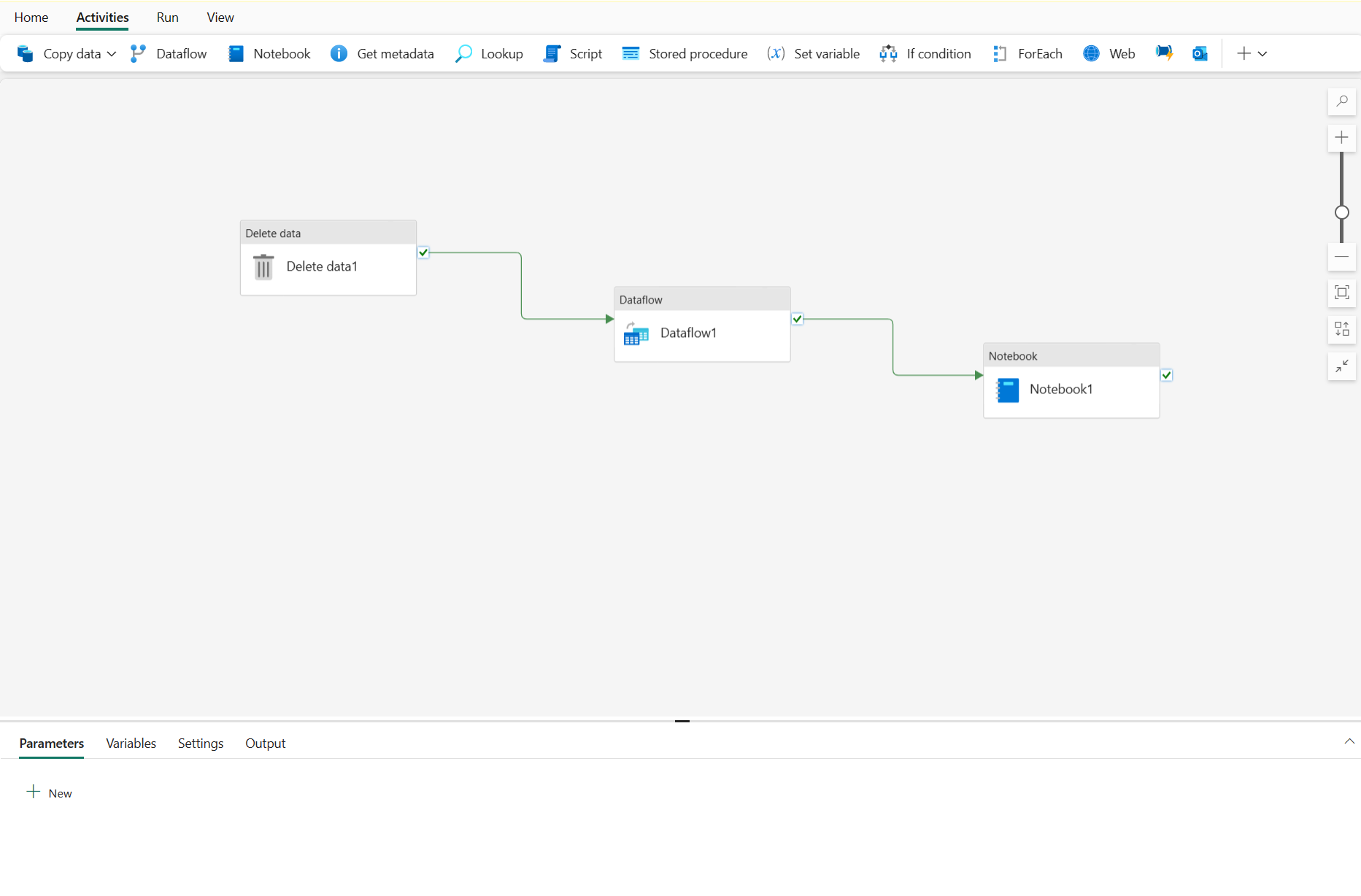
Activities are the executable tasks in a pipeline. You can define a flow of activities by connecting them in a sequence. The outcome of a particular activity (success, failure, or completion) can be used to direct the flow to the next activity in the sequence.
There are two broad categories of activity in a pipeline.
- Data transformation activities – activities that encapsulate data transfer operations, including simple Copy Data activities that extract data from a source and load it to a destination, and more complex Data Flow activities that encapsulate dataflows (Gen2) that apply transformations to the data as it is transferred. Other data transformation activities include Notebook activities to run a Spark notebook, Stored procedure activities to run SQL code, Delete data activities to delete existing data, and others. In OneLake, you can configure the destination to a lakehouse, warehouse, SQL database, or other options.
- Control flow activities – activities that you can use to implement loops, conditional branching, or manage variable and parameter values. The wide range of control flow activities enables you to implement complex pipeline logic to orchestrate data ingestion and transformation flow.
oracle peoplesoft training courses malaysia
Leave a Reply