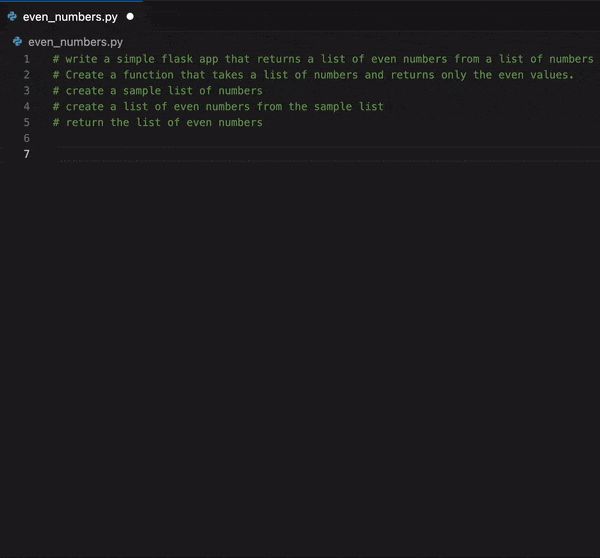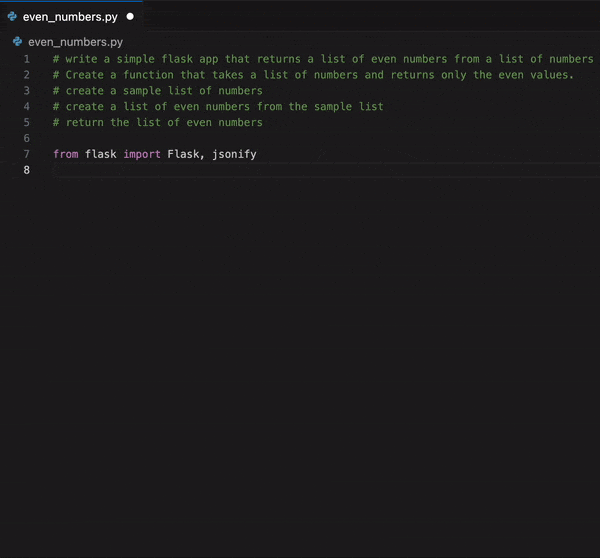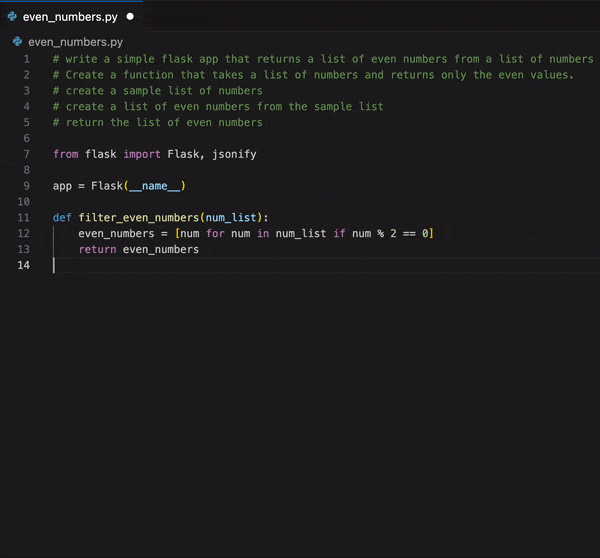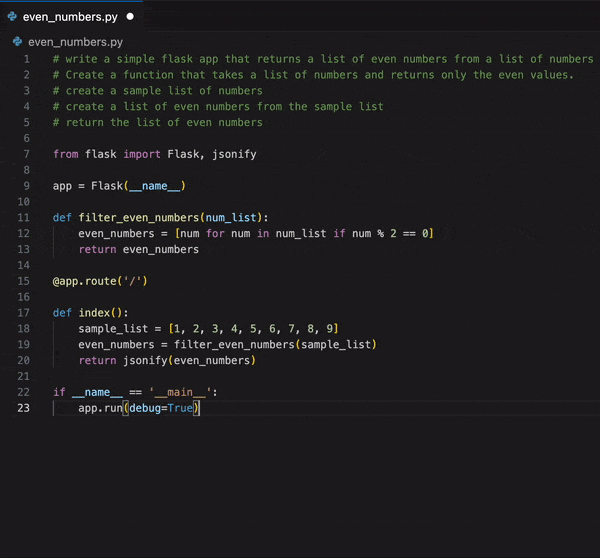
GitHub Copilot is powered by Large Language Models (LLMs) to assist you in writing code seamlessly. In this unit, we focus on understanding the integration and impact of LLMs in GitHub Copilot. Let’s review the following topics:
- What are LLMs?
- The role of LLMs in GitHub Copilot and prompting
- Fine-tuning LLMs
- LoRA fine-tuning
What are LLMs?
Large Language Models (LLMs) are artificial intelligence models designed and trained to understand, generate, and manipulate human language. These models are ingrained with the capability to handle a broad range of tasks involving text, thanks to the extensive amount of text data they’re trained on. Here are some core aspects to understand about LLMs:
Volume of training data
LLMs are exposed to vast amounts of text from diverse sources. This exposure equips them with a broad understanding of language, context, and intricacies involved in various forms of communication.
Contextual understanding
They excel in generating contextually relevant and coherent text. Their ability to understand context allows them to provide meaningful contributions, be it completing sentences, paragraphs, or even generating whole documents that are contextually apt.
Machine learning and AI integration
LLMs are grounded in machine learning and artificial intelligence principles. They’re neural networks with millions, or even billions, of parameters that are fine-tuned during the training process to understand and predict text effectively.
Versatility
These models aren’t limited to a specific type of text or language. They can be tailored and fine-tuned to perform specialized tasks, making them highly versatile and applicable across various domains and languages.
ccie certification training courses malaysia